前言
通过分布式系统-分布式事务中介绍,TCC解决分布式事务的基本流程为:在Try阶段,主业务服务记录交易信息,并通知从业务服务锁定事务需要的资源。如果从业务都能够锁定事务所需要的资源,主业务则通知从业务真正提交锁定的资源,否则通知从业务回滚锁定的资源。本文依托该理论思想,实现分布式系统下的转账功能,以便进一步加深理解TCC。
业务描述
客户端发起转账请求,事务管理服务接收请求后,开始TCC转账流程,事务管理服务、转入服务、转出服务都是独立的服务,并且每个服务拥有自己独立的数据库管理数据。
要求:
事务管理服务、转入服务、转出服务必须幂等,不重复处理同一笔交易信息
服务可以水平扩展,既能够以集群的方式部署接收请求,也能够以分布式主从架构部署提供服务
保障资金安全的最高优先级,转账过程中不能出现资金错误
在保障资金安全的前提下,尽可能提高系统性能
技术栈
服务对外的通信框架:SpringBoot (RESTFul API)
服务之间的通信框架:Dubbo (RPC)
服务注册发现中心:Zookeeper
数据库:Mysql
数据库分片框架:Mycat
基础设施平台:Docker
系统架构
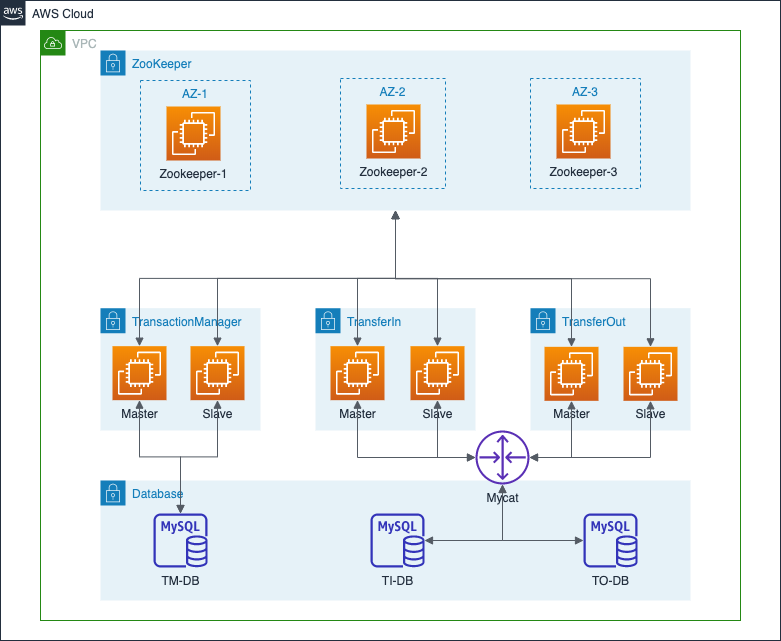
分布式主从架构部署模式,事务管理服务、转入服务、转出服务都注册到Zookeeper,并且服务分为主从节点,对外只有主节点提供服务。当主节点出现异常时,从节点选主成为新的主节点对外提供服务。详情如下图所示:
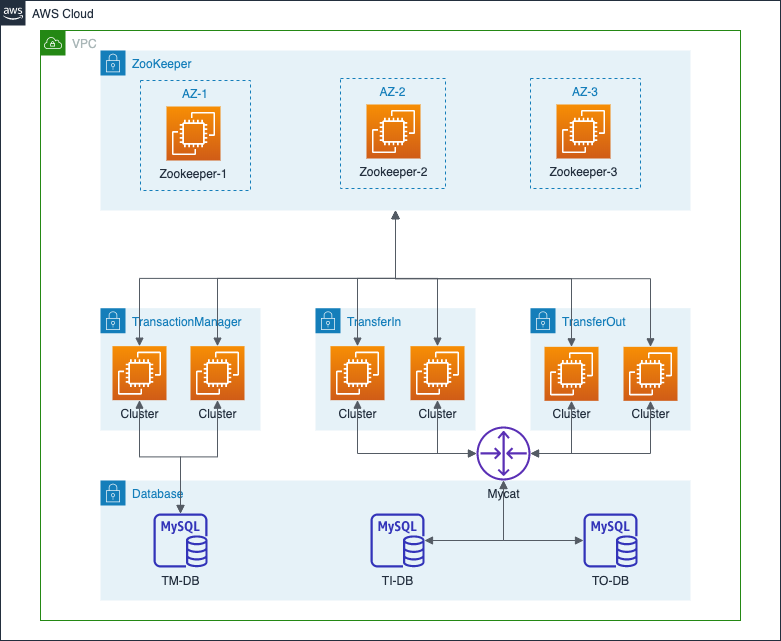
集群架构部署模式,事务管理服务、转入服务、转出服务以集群方式注册到Zookeeper,同时有多个节点对外提供服务。任何一个服务的某个节点出现异常,对系统无影响。服务之间应用简单的负载均衡算法完成集成。详情如下图所示:
TCC交互流程
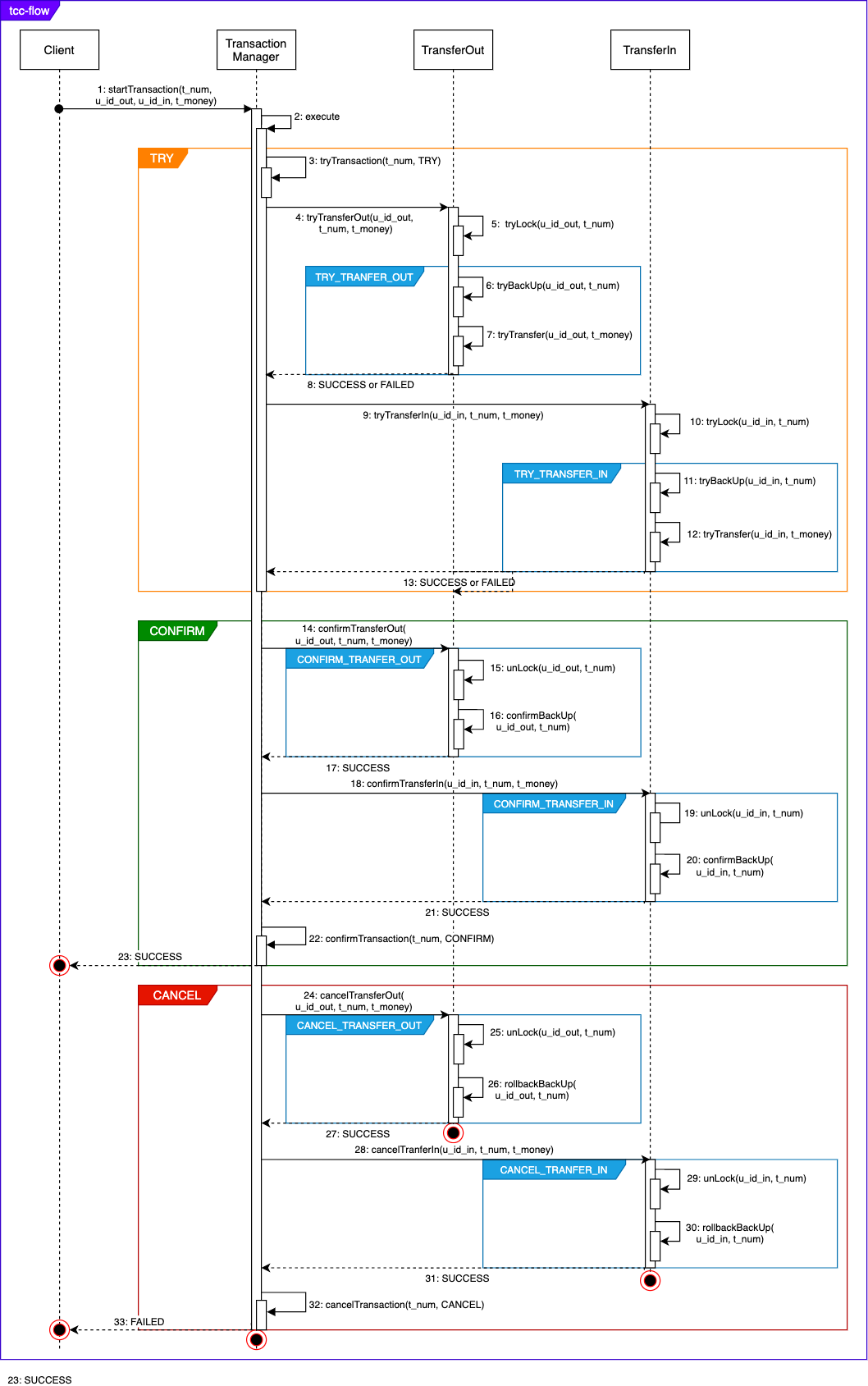
流程介绍:
由于事务管理服务、转入服务、转出服务是分布式主从架构或者集群架构的部署模式,可以保障服务之间的重试是可以立即恢复之前的操作,且所有服务都是幂等的。
TransactionManager:
- TRY阶段,接收客户端发起的转账请求,在数据库记录交易信息,并标记为TRY状态,然后通知TransferOut服务和TransferIn服务开启TRY流程
- 当收到【8】和【13】的消息都是SUCCESS则进入CONFIRM阶段,否则进入CANCEL阶段
- CONFIRM阶段,通知TransferOut服务和TransferIn服务进入CONFIRM阶段,然后将交易信息更新为CONFIRM状态并返回SUCCESS
- 消息【17】和【21】只返回SUCCESS的原因是有重试机制,一直重试直到返回SUCCESS才结束
- CANCEL阶段,先通知TransferOut服务和TransferIn服务进入CANCEL阶段,然后将交易信息更新为CANCEL状态并返回FAILED
- 消息【27】和【31】只返回SUCCESS的原因是有重试机制,一直重试直到返回SUCCESS才结束
- CONFIRM阶段和CANCEL阶段是可以异步化的,也就是只要TRY阶段结束就可以将结果返回给客户端,但是当CONFIRM或者CANCEL阶段在异步化过程中出现异常时,尤其是CANCEL阶段,则全局数据就会出现不一致,且恢复过程非常的困难,因此本示例采取同步的方式处理CONFIRM和CANCEL阶段
TransferOut:
- TRY阶段,先根据用户ID和事务ID获取全局锁,该全局锁是TransferOut服务和TransferIn服务共享,然后执行【6】和【7】
- 操作【5】将获取全局锁,只有获取了全局锁才会执行后续的流程,同一个用户的同一笔交易记录可以重复获取全局锁
- 操作【6】将备份当前用户账户数据在执行前和执行后的状态
- 操作【6】和【7】属于同一个本地事务,任何一个失败,数据都会回滚并返回异常信息
- CONFIRM阶段,更新备份数据的状态,并且释放全局锁
- 操作【15】和【16】是幂等的,允许无限次重试
- 操作【15】和【16】属于同一个本地逻辑事务中,任何一个失败,数据都会回滚并返回异常信息
- CANCEL阶段,用备份数据还原用户账户记录,并更新状态和释放全局锁
- 操作【25】和【26】是幂等的,允许无限次重试
- 操作【25】和【26】属于同一个本地逻辑事务中,任何一个失败,数据都会回滚并返回异常信息
TransferIn:
- TRY阶段,先根据用户ID和事务ID获取全局锁,该全局锁是TransferOut服务和TransferIn服务共享,然后执行【11】和【12】
- 操作【10】将获取全局锁,只有获取了全局锁才会执行后续的流程,同一个用户的同一笔交易记录可以重复获取全局锁
- 操作【11】将备份当前用户账户数据在执行前和执行后的状态
- 操作【11】和【12】属于同一个本地事务,任何一个失败,数据都会回滚并返回异常信息
- CONFIRM阶段,更新备份数据的状态,并且释放全局锁
- 操作【19】和【20】是幂等的,允许无限次重试
- 操作【19】和【20】属于同一个本地逻辑事务中,任何一个失败,数据都会回滚并返回异常信息
- CANCEL阶段,用备份数据还原用户账户记录,并更新状态和释放全局锁
- 操作【29】和【30】是幂等的,允许无限次重试
- 操作【29】和【30】属于同一个本地逻辑事务中,任何一个失败,数据都会回滚并返回异常信息
异常分析:
- 异常发生在【3】之后,【14】或【24】之前,返回超时,交易记录处于TRY状态,TransferOut服务和TransferIn服务用户数据状态不确定
- 客户端发起重试,查询到交易记录为TRY状态,重启TRY阶段流程,【最终全局数据一致】
- 异常发生在【14】或【24】之后,【22】或【32】之前,返回超时,交易记录处理TRY状态,TransferOut服务用户数据状态不确定,TransferIn服务用户数据状态不确定
- 客户端发起重试,查询到交易记录为TRY状态,重启TRY阶段流程,【最终全局数据一致】
- 异常发生在【22】或【32】之后,返回超时,【全局数据一致】,处于CONFIRM或CANCEL状态
- 客户端发起重试,直接返回SUCCESS或FAILED
- 异常发生在TransferOut服务或TransferIn服务内部,不影响全局数据一致性
- TRY阶段,TransactionManager会决定进入CANCEL阶段
- CONFIRM或CANCEL阶段,TransactionManager会一直重试,直到返回正常结果
总结
上述过程描述了一个详细的TCC流程,具体的代码可以在这里下载distributed-transaction。
本示例以资金安全为第一优先级,很多能够异步化的操作都改成了同步操作,因为异步化虽然对性能有提高,但是当服务在进行异步化操作的过程中一旦出现异常,数据状态的恢复比较麻烦,并且异步化也不会带来更高的性能收益。(性能的主要提升在于TCC的过程没有在资源层加锁,用户A进行转账时,其他用户是不会被锁住,也可以同时进行转账操作)
与此同时,本示例在进行转账过程时,需要根据用户ID和交易号获取全局锁,也就是说同一个用户一次只能进行一次转账。这样做的目的是保障在CANCEL阶段,用户的数据不会出现误差,能够正常回滚用户数据 (大家可以思考下,如果没有全局锁,CANCEL阶段会发生什么?)。但是这种情况,对于高频率的转账账户是一个比较大的挑战,所以我们可以继续思考,如何对其进行优化。
欢迎大家在评论区讨论各种分布式系统相关的内容。