前言
在分布式系统-Raft共识算法中,我们详细的描述了共识算法如何让系统内部状态保持一致性的,而我们今天介绍的分布式事务,也是为了解决一致性问题,但是它们有什么区别呢?
回答这个问题,我们需要从它们解决的问题域思考。共识算法主要是为了解决选主以及日志同步问题,保证集群状态的一致性,最主要的应用领域是依赖主从协调的分布式系统,共识算法可以帮助管理集群。分布式事务主要解决在分布式系统中的事务一致性,保证系统内部数据的一致性,主要的应用领域是需要事务特性的分布式系统,保证系统在执行同一操作时,要么同时成功,要么同时失败。所以我们一定不要混淆这两者,虽然都是解决一致性的问题,但是问题域是不一样的。
本地事务
在正式介绍分布式事务之前,我简单回顾一下本地事务,也就是数据库事务的ACID特性
- A (Atomicity):原子性,数据库事务中的所有操作,要么全部成功,要么全部失败
- C (Consistency):一致性,数据库中的数据,只能有一个状态转换为另一个状态,不存在软状态
- I (Isolation):隔离性,数据库事务执行中的中间结果,对其他事务是不可见的
- D (Durability):持久性,数据库事务一旦提交,就无法改变
除此之外,本地事务还可以将事务隔离级别划分为如下几等:
- READ UNCOMMITTED:该隔离级别为最低的隔离级别,允许事务读取其他事务还未提交的记录,并发性能最好,但是会产生脏读,事务会读取到其他事务操作过程中的数据,从而导致最终数据不一致
- READ COMMITTED:该隔离级别允许事务读取其他事务已经提交的记录,因此该隔离级别下,事务不会读取到脏数据,但是事务在两次相同的查询条件下,会读到不同的结果,也就是说该隔离级别不能保证数据的可重复性读
- REPEATABLE READ:该隔离级别通过行锁和间隙锁保证数据的可重复性读,也就是事务内同一查询条件无论执行多少次,查询的结果都是一致的,该隔离级别也是很多数据库的默认事务隔离级别,例如mysql
- SERIALIZABLE:该隔离级别是事务的最高隔离级别,串行隔离级别,也就是一次只允许一个事务执行,并发性能是最差的,一般是数据库实现分布式事务时采取的隔离级别
分布式事务
本地事务解决了单机环境下的事务一致性问题,基本上市面上的所有数据库软件都实现了事务机制。在单机环境下,事务问题本质就是多线程环境下的数据安全性问题。在分布式事务环境下,数据是存储在不同的机器中,每次数据的修改都需要发生网络请求,例如支付服务,需要从账户A中扣钱,账户B中加钱,管理账户A的服务在扣完前后就需要发网络请求告诉管理账户B的服务,这时候如果管理账户B的服务出现异常,那账户A和账户B的数据状态就不一致了。为了保证分布式环境下的事务一致性,我们需要引入分布式事务来解决这类问题。
分布式事务的解决方案有如下几类:2PC,TCC,Message Queue,Saga Pattern, 接下来将分别介绍这种方法的基本思路,详细的细节将通过后续的实战内容深入讨论。
- 2PC:两阶段提交,该方法是最核心的思路,其他的方法都是基于该方法的思想做的优化。2PC中有事务管理器和资源管理器两种角色,事务管理器负责协调资源管理器,资源管理器对应本地事务数据库。首先,事务管理器通知资源管理器开始执行第一阶段事务,资源管理器则会在本地执行对应的事务操作,并把结果告知事务管理器。第二阶段,当事务管理器收到所有资源管理器操作成功的结果后,则通知资源管理器提交它们的本地事务,否则通知它们回退本地事务。在整个过程中,事务管理器需要记录各种中间状态,以保证最终三方状态的一致性。最开始事务管理器要记录prepare状态,该状态下,事务管理器发送事务执行的请求到资源管理器。然后当事务管理器收到所有资源管理器操作成功的结果后,会把prepare状态改为commit状态,并通知资源管理器提交本地事务。否则将prepare状态改为rollback状态,并通知资源管理器回滚本地事务。如下图所示:
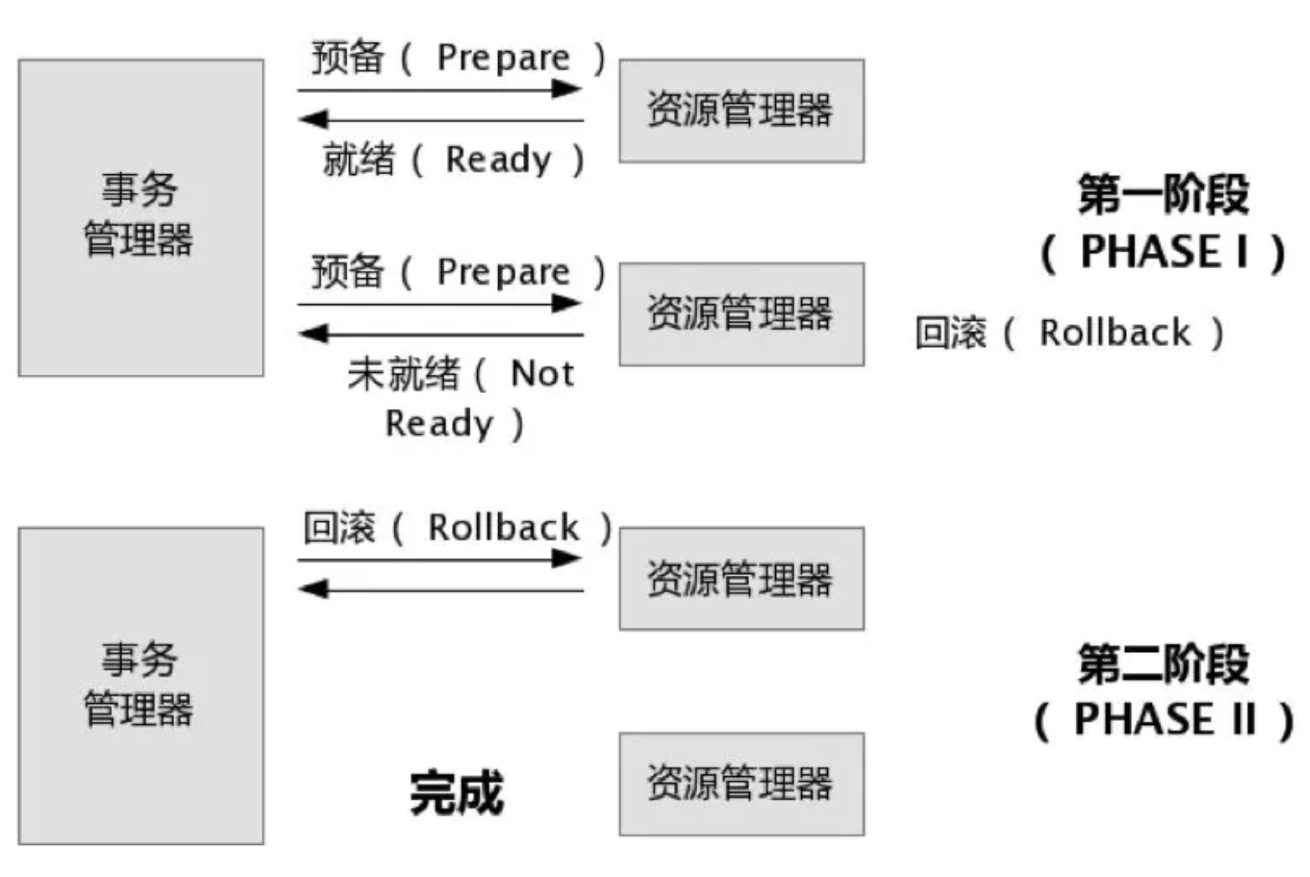
从上面的描述可以看出,完成2PC需要多个节点的多次交互,并且每次交互都需要更新状态,因此在分布式环境中,一旦某个节点出现异常,就会导致数据的不一致,并且数据的恢复非常难。同时该方法是在数据库层面实现的,需要所有参与2PC的数据库节点都转换为SERIALIZABLE的事务隔离级别,对系统的性能影响非常大。因此在实际的生产环境下,很少直接使用2PC来解决分布式事务的问题,更多的是使用接下来介绍的几种方法。
- TCC:TCC代表Try,Confirm,Cancel。其思路跟2PC基本一样,只不过TCC是在业务层面完成的事务协调管理。在Try阶段,主业务服务记录交易信息,并通知从业务服务锁定事务需要的资源。如果从业务都能够锁定事务所需要的资源,主业务则通知从业务真正提交锁定的资源,否则通知从业务回滚锁定的资源。该方法在实际操作时,需要在Try阶段思考如何锁定资源、在Cancel阶段如何将锁定的资源安全的回滚等问题,在后续的实战中,我将进一步深入的描述这些问题的解决方案。
- Message Queue:使用Message Queue解决分布式事务问题的思路与TCC基本一致,唯一的区别在于基础架构的变化,基本的TCC思路,服务之间可以使用RPC或者Restful API的方式通信,而Message Queue则通过消息Broke进行服务之间的通信。第一阶段,主业务服务发送事务消息给消息Broke,消息Broke将事务消息推送给从业务,从业务锁定相关资源,并将结果发送给消息Broke,消息Broke将结果通知主业务服务。第二阶段主业务将提交或者回滚的消息发送给消息Broke,消息Broke分发对应的消息给从业务服务,从业务服务提交或者回滚对应的操作。
- Saga Pattern:Saga Pattern是微服务中提出的解决分布式问题的一种解决方案,其核心思想是在执行正向操作前,记录对应的补偿事务,当被调服务发生异常时,服务调用方执行补偿事务恢复数据。例如A服务在执行扣钱服务前,先记录对应的反向事务,然后在执行扣钱操作并调用B服务执行加钱操作。如果B服务返回成功的结果,A服务则删除对应的补偿事务记录,否则A服务执行对应的补偿事务,还原数据。
总结
经过上面的分析,2PC,TCC,Message Queue,Saga Patthern都能给解决分布式事务的提高不错的思路,但是这几种方案都有一定的不足,比如2PC是在资源层的控制,对系统性能影响很大,而且开放性差;TCC对业务的侵入很深,为了保障TCC整个流程的完整,需要多个额外的数据表存储对应的状态;Message Queue则跟TCC一样,虽然引入了消息Broke解耦了主服务方和从服务方,但是增加了额外的消息消费复杂度;Saga Pattern在生成补偿事务时,复杂度也会随着正向操作的复杂度增加而增加。并且这几种方案在事务处理过程中,一旦某个服务发生异常,需要完全恢复数据也比较复杂。我们需要在实战过程中,分析各种异常,并找出对应的解决方案。
最后推荐一下Seata,一个分布式事务处理框架,实现了本文中多种思路的解决方案。
欢迎大家在评论区讨论各种分布式系统相关的内容。