前言
由于分布式系统是由一群相互协作的系统组成,每个组成部分只负责一小部分功能,并且经过我们在分布式系统-关键特性中的分析,每个组成部分都是不稳定的,因此系统需要一个“管理者”的角色管理分布式系统中的所有组成部分。
我们可以拿现实中的例子来说明这个情况:在软件研发团队中,我们会分开发团队、测试团队、维护团队等等多个团队,每个团队承担不同的职责,典型的分布式系统特征。如何保证每个团队的工作内容不重叠?如何拉通每个团队的工作进度以保证大家的步调是一致的?现实中,我们会选出一位项目管理者角色——PM。通过PM对项目的全局管控,协调不同团队之间的协作以确保不出现上述问题。例如:当某些团队出现人员变动,PM会补充新员工以替代旧员工;当PM离职了,团队会选出新的PM来替代旧的PM。
同样,在分布式系统环境中,我们也需要一位“PM”,只不过这位“PM”的角色比我们真实社会中PM的职责简单一点。这位“PM”需要知道系统中每台机器的状态,需要知道在下达命令时哪些机器执行了而哪些系统没有执行,这样就可以知道如何去同步所有机器之间的状态,以确保所有系统的状态一致性。
那么,我们如何选出这位“PM”呢?现实生活中我们是有岗位、职责定义,并通过招聘找到我们的PM。但是,在分布式系统中,并没有那么复杂,是通过即将要介绍的共识算法来选取“PM”,并且给它命名为主节点。(本文中打引号的PM等同于主节点)
Raft Consensus Algorithm
分布式系统中,有很多共识算法,例如Paxos,Raft,Chubby等等,如果感兴趣,大家可以到awesome-consensus查阅更多的资料。本文主要讨论Raft共识算法,Raft的设计初衷是觉得Paxos太难懂了,实现也很复杂,在实际工程中非常难落地。因此需要一个既简单易懂,又能够在实际工程中落地的共识算法,所以就有了Raft共识算法。
要理解Raft算法,我们得分两个部分,第一部分就是选主,第二部分则是日志同步。
第一部分——选主:
首先,我们引入几个名词,分别对应分布式系统每个参与者的不同状态,分别为主节点、候选节点、跟随节点。如下图所示:(图片来源于Raft Paper)
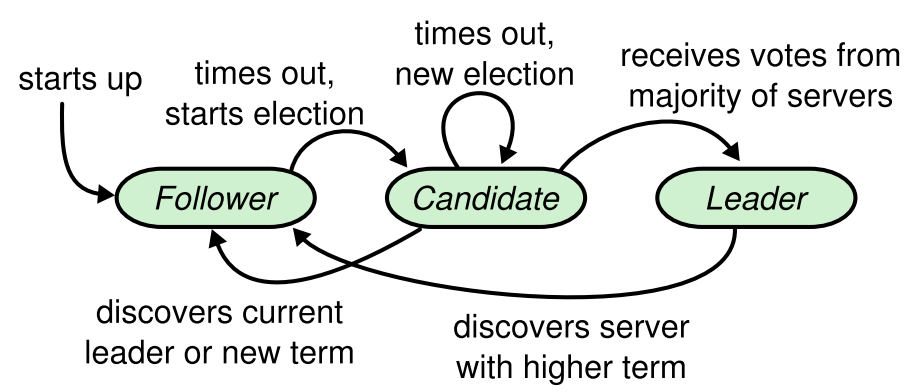
- 主节点负责下达命令,监控其他节点的状态,发布心跳检测指令,管理其他节点
- 候选节点表示该节点正在参与选主的过程
- 跟随节点也可以叫做从节点,负责执行主节点下发的命令
选主过程为:
- Step1:在分布式系统初始化阶段,每个参与者都是跟随节点,并且都在本地维护一个Term,(Term就是一个简单的数字,表示这是哪个阶段,类比到现实世界中的总统选举就是第几届总统,系统中则是某节点是第Term阶段的主节点) 它们都在监听来自主节点心跳检测命令
- Step2:一旦有跟随节点在超过它的最长等待时间都没有收到主节点的心跳检测命令时,它就会转化成候选节点,并把本地的Term加1,(由于每个参与者都在本地维护这个Term,并且Term会被主节点同步,所以只要在本地加1就可以保证自己的Term比其他节点的Term都大) 并发起选主投票
- Step3:其他跟随节点收到来自候选节点的投票信息后,会对比候选节点发来的Term,如果比自己本地的Term值更大,就会发送同意票,否者就会发送反对票,且每个跟随节点只能给一个Term值投一票,不能重复投票
- Step4:候选节点收到所有的投票结果后,如果同意票的数量超过整个系统中的Quorum, 则选主成功,否者则失败 (选主失败后回到Step1重新开始新一轮的选主)
关于Quorum的解释:假设n为分布式系统总的节点数,Quorum的取值必须大于等于(2/n+1),例如3个节点的分布式系统,Quorum至少等于2;5个节点的分布式系统,Quorum至少等于3,且由于这个原因我们一般会把分布式系统的节点数设置为基数——2n+1,这样系统就可以在n个节点失效的情况下还能保持正常,也就是说在有2n+1个节点数的分布式系统可以在有n个节点失效的情况保持正常。
- Step5:候选节点成为主节点后,会立刻给其他节点发送心跳命令,所有节点立刻转化成跟随节点,并开始等待主节点的日志同步命令
- Step6:候选节点成为主节点后,会将自己本地已经提交的日志状态发送给跟随节点,让跟随节点与主节点状态保持一致
- Step7:当主节点由于发送网络分区导致不可达时,回到Step1重新开始新一轮的选主
在上述选主过程中,存在如下几点问题需要单独拿出来解释,以帮助大家更加深入的理解该算法。
- 问题一:当所有跟随节点同时到达最大等待时间时如何处理?
如果所有跟随节点在同一时间转为候选节点并开始选主,这样可能导致永远都选不出主节点。(所有节点都在参与选主,没有节点会投同意票) 解决方案就是所有跟随节点的最大等待时间随机设定在一个范围区间内。
- 问题二:候选节点在选主过程中,收到了其他选主成功节点的心跳命令该如何处理?
候选节点在选主过程中一旦收到新的主节点发来的心跳命令,则会立刻转变成跟随节点,并开始等待新的主节点的日志同步命令。
- 问题三:如一个刚加入系统的节点选主成功了,其他节点已经复制的日志如何处理?(参与选主节点的日志很旧,会不会冲掉拥有新日志节点的记录)
这个问题分为两个部分回答,第一部分则是在选主过程中,跟随节点不但要判断Term值的大小,还要判断候选节点已经提交日志的更新程度,如果候选节点提交日志的更新程度没有跟随节点的新,则跟随节点还是会投反对票,这样可以保证拥有更旧日志的节点不可能成为主节点;第二部分则是候选节点成为新的主节点后,会把自己本地提交的日志记录同步给跟随节点,让跟随节点与主节点保存状态一致。(如果主节点与跟随节点有很多提交的日志记录不一致,主节点会从最新的提交日志开始往前回找,直到找到分歧点,并把从分歧点开始到最新的提交日志这段记录发送给跟随节点,让其保持同步状态)
第二部分——日志同步:
通过上述选主过程,分布式系统就可以成功选出主节点了。有了主节点后,整个分布式系统就交给它管理了。接下来就可以开始真正的让系统执行任务了。这个过程叫做日志同步,也可以认为是执行命令,同步数据的过程。
执行写命令:系统外部的写命令都会发送到主节点,如果写命令发送到了跟随节点,则跟随节点会把写命令转发到主节点。主节点在接收到了写命令后会将此命令广播给所有的跟随节点,一旦有超过Quorum数量的跟随节点执行写命令成功,主节点就会认为该写命令执行成功,否者则认为执行失败。
同步执行失败的跟随节点:执行写命令,如果少部分跟随节点执行失败,主节点则会一直尝试将该命令发送给执行失败的跟随节点以保证它们达到同步状态。这时如果主节点突然失效,则会触发新的选主过程,且由于这条写命令在大部分跟随节点都执行成功了的,新的主节点也会包含这条最新的写命令,(执行失败的跟随节点由于提交日志的更新程度太旧而不可能选主成功) 在接下来的日志同步过程,新的主节点还是会不断尝试把刚刚的写命令发送给执行失败的跟随节点,以保证它们达到同步状态。
执行读命令:分布式系统中的每台机器都可以响应外部的读命令。
结语
到目前为止,我们已经把Raft共识算法的逻辑已经基本介绍完毕了,选主和日志同步这两个部分是Raft共识算法的核心思想,并且也是很多类似Raft共识算法的核心思想。掌握了这两个部分的处理逻辑,我们才算真正的懂了Raft共识算法的思想。
最后,我们可以看出Raft共识算法在CAP Theorem选择的是偏向CP的系统设计,因为每个写的操作,必须要求至少有Quorum数量的节点写成功才会认为是真正的写成功,确保系统中大部分节点的状态是一致的;同时它也拥有很高可用性,因为它能容忍小于Quorum数量的节点失效,并且对外还是保持正常状态,也就是说在有2n+1个节点数的分布式系统可以在有n个节点失效的情况保持正常。
所以不难看出,在实际的分布式系统设计中,关于CAP Theorem的选择不是非黑即白的CP和AP的选择,而是会在CAP三个特性中找到一个的平衡点,让我们的系统在发生网络分区的情况下,既能在一定程度上保障系统的一致性,同时还能够让系统保持一定程度的可用性。
课外阅读:大家可以思考一下,如果要设计偏向AP的系统,该如何考虑?参考资料Redis Cluster consistency guarantees
欢迎大家在评论区讨论各种分布式系统相关的内容。